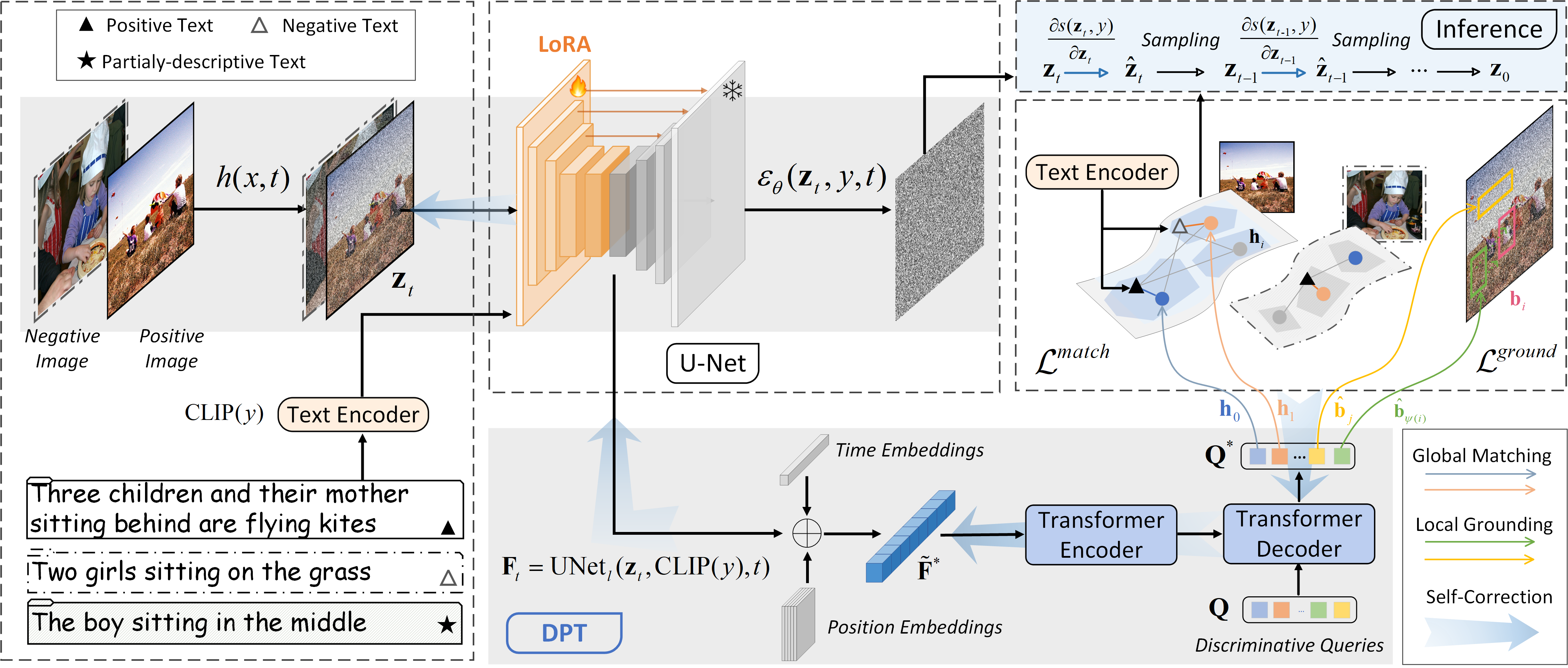
Framework
Schematic illustration of the proposed discriminative probing and tuning (DPT) framework. We first extract semantic representations from the frozen SD and then propose a discriminative adapter to conduct discriminative probing to investigate the global matching and local grounding abilities of SD. Afterward, we perform parameter-efficient discriminative tuning by introducing LoRA parameters. During inference, we present the self-correction mechanism to guide the denoising-based text-to-image generation.